
Байесовский классификатор
Евгений Борисоввторник, 3 декабря 2013 г.
В этой статье мы рассмотрим математический метод, который называется байесовский классификатор.
1 Введение
Байесовский классификатор относится к методам машинного обучения ”с учителем”, но в отличии от перцептрона и других подобных моделей, он не требует длительной процедуры обучения. Можно сказать, что эта процедура в данном случае вырождена.
Классификатор содержит в себе учебную выборку для каждого класса и каждый вход последовательно сравнивается с этими наборами по определённому алгоритму, далее выбирается наиболее вероятный класс.
2 Принцип максимума апостериорной вероятности
Рассмотрим множество учебных примеров ( X,Y ) , здесь X ∋ x = ( ξ 1 , … ,ξ n ) – объекты, Y – классы. Классификатор должен отображать объекты в классы с минимальной вероятностью ошибки
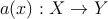
При этом предполагаем, что все признаки { ξ i } объекта независимы друг от друга, из-за этого ограничения байесовский классификатор называют ”наивным”.
Байесовский классификатор основывается на принципе максимума апостериорной вероятности
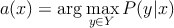
P ( y | x ) – вероятность события - x принадлежит классу y .
Согласно теореме об оптимальном байесовском классификаторе [ 1 ] , a ( x ) выглядит следующим образом
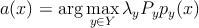
|
(1) |
где λ y – потеря при ошибочной классификации для класса y , будем считать, что в случае правильного ответа потерь нет, P ( y ) ≡ P y – априорная вероятность класса y (определяется долей объектов x y класса y в общем наборе X ), p y ( x ) – плотность распределения x y из класса y .
3 Восстановление плотности распределения
Для построения классификатора по ( 1 ) необходимо восстановить плотность распределения p y по учебной выборке ( X,Y ) . Не будем здесь детально рассматривать методы восстановления плотностей и приведём сразу решение задачи, но прежде отметим важное обстоятельство. Поскольку мы приняли ограничение о независимости признаков ξ i объектов x ∈ X то искомую n -мерную плотность можно рассматривать как произведение одномерных плотностей.
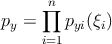
Для восстановления плотности по выборке воспользуемся оценкой плотности Парзена-Розенблатта [ 1 ] .
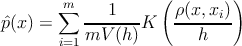
где m – количество элементов выборки X ∋ x i , ρ – мера на X , h – окрестность x i (”ширина окна”), K – функция ядра, V ( h ) – нормирующий множитель.
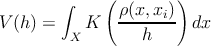
В качестве функции ядра будем использовать ядро Епанечникова
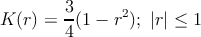
|
(2) |
будем использовать Евклидову метрику
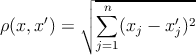
|
(3) |
Ещё необходимо выбрать ширину окна h . Этот параметр можно задавать разным способом. Здесь будем использовать метод скользящего контроля Leave One Out. Параметр h выбираем перебором, каждый раз проверяя суммарную ошибку на учебном множестве, при этом из учебного набора удаляется текущий (проверяемый) пример.
![∑l
LOO (h,X ) = [a(xi;{X ∕xi},h) ⁄= yi] → min
i=1 h](/content/ml-bayes.html/index8x.png)
4 Байесовский классификатор
В конечном итоге классификатор описывается следующим соотношением.
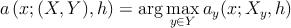
где ( X,Y ) - учебная выборка, λ y - коэффициент потерь на классе y , P y - априорная вероятность y , l y - количество объектов x в классе y , ρ – мера ( 3 ) на X , K – функция ядра ( 2 ).
|
|
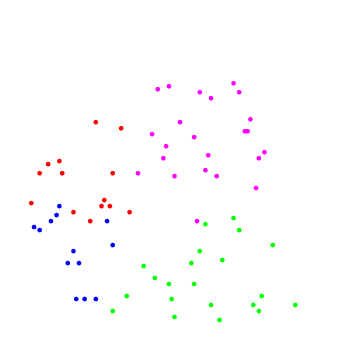
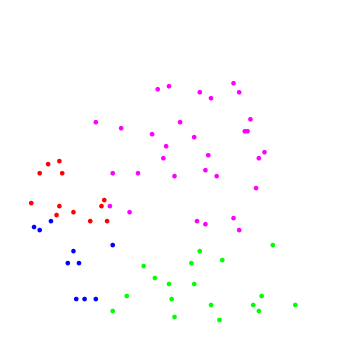
| Рис.1: учебный набор | Рис.2: результат работы |
Реализация в системе Octave [ здесь ].
Список литературы
[1] Воронцов К.В. Статистические методы классификации – http://shad.yandex.ru/lectures/machine_learning.xml
