
Классификатор на основе логистической регрессии.
Евгений Борисов
Понедельник, 27 Май 2013 г.
В этой статье мы поговорим об математическом методе логистической регрессии (logistic regression) и классификаторе (ЛРК) на основе этого метода [1,2]. ЛРК используется для бинарной классификации, т.е. выдаёт вероятность P принадлежности входа к данному классу, для работы с несколькими классами используются несколько ЛРК в результате выбирается ЛРК показавший max P значение для данного входа, а учебный набор из N классов для каждого ЛРК преобразуется к бинарному - "мой класс и все остальные".
Рассмотрим набор данных из m элементов размера n + 2
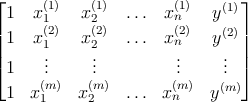
где x j ( i ) ∈ ℝ , y ( i ) ∈{ 0 , 1 }
Классификатор в данном случае это функция (гипотеза), которая выглядит следующим образом.
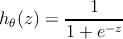
где z = z ( x ) это определённая функция, о которой мы поговорим ниже.
1 Линейный классификатор
Задав z ( x ) следующим образом
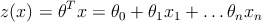
мы получим линейный классификатор.
Легко видеть, что в этом случае h 𝜃 ( 𝜃 T x ) является искусственной нейронной сетью из одного нейрона с сигмоидной функцией активации, который имеет n входов.
Для обучения классификатора будем применять метод градиентного спуска. Функция оценки (cost function) будет выглядеть следующим образом.
![m
1-∑ [ (i) (i) (i) (i) ]
J (𝜃) = − m y ⋅ log (h 𝜃(x )) + (1 − y )log(1 − h𝜃(x ))
i=1](/content/ml-regression-class.html/index3x.png)
Коэффициенты 𝜃 будут изменяться согласно следующему соотношению.
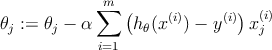
Линейный классификатор имеет известные ограничения, он строит только линейные разделяющие повехности. Например, он в принципе не способен выделить в двумерном пространстве признаков область в форме круга.
2 Нелинейный классификатор
Для выделения в пространстве признаков областей сложной формы можно воспользоваться нелинейным классификатором.
Для этого можно определить z ( x ) как полином второй, третей или более степеней. Например, для двумерного пространства признаков и степени полинома n = 4
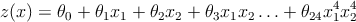
В процессе градиентного спуска коэффициенты 𝜃 будут изменяться согласно следующему соотношению.
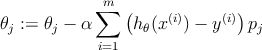
3 Регуляризация
При работе с классификаторами может возникать проблема т.н. переобучения (underfitting), когда ошибка обучения падает почти до нуля, но при этом растёт ошибка обобщения, т.е. классификатор хорошо понимает только учебный набор.
Этот эффект может возникать из-за излишне сложной модели т.е. избыточно сложная z ( x ) и/или слишком много признаков x .
Для подавления эффекта переобучения можно применять разные методы, один из них это регуляризация – уменьшение значений коэффициентов 𝜃 .
Достигаеться этот результат путём добавления нового слагаемого к функции оценки
![m n
1-∑ [ (i) (i) (i) (i) ] -λ--∑ 2
J (𝜃) = − m y ⋅ log(h 𝜃(x )) + (1 − y )log (1 − h 𝜃(x )) + 2m 𝜃j
i=1 j=1](/content/ml-regression-class.html/index7x.png)
и соотношению изменения коэффициентов процессе градиентного спуска
![( ∑m ( )
||| 𝜃0 :=𝜃0 − α 1- h𝜃(x(i)) − y(i)
|{ m i=1
[ m ]
||| -1 ∑ ( (i) (i)) λ-
|( 𝜃j :=𝜃j − α m h𝜃(x ) − y pj + m 𝜃j
i=1](/content/ml-regression-class.html/index8x.png)
где 0 < α < 1 – параметр (скорость обучения), p j – произведение значений x при коэффициенте 𝜃 j ( j = 1 , … ,n ) полинома z(x)
Эта модификация подавляет (penalize) рост значений 𝜃 в процессе обучения. Необходимо выбрать удачный параметр λ (regularization parameter), если он будет слишком мал то эффекта не будет, если он будет слишком велик то обратит в ноль все 𝜃 и z ( x ) выродится в прямую z ( x ) ≈ 𝜃 0
Далее приведен наглядный пример, нелинейный ЛРК с регуляризацией выделяет в двумерном пространстве признаков область в форме круга.
|
|
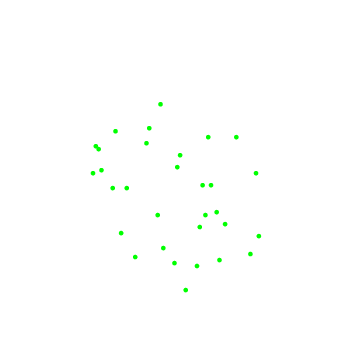
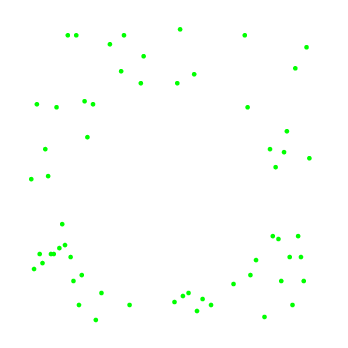
|
|
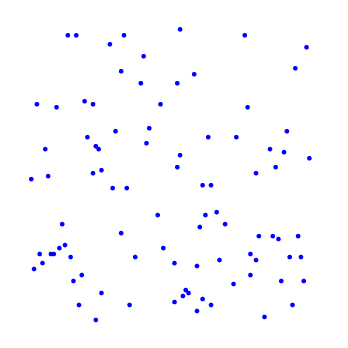
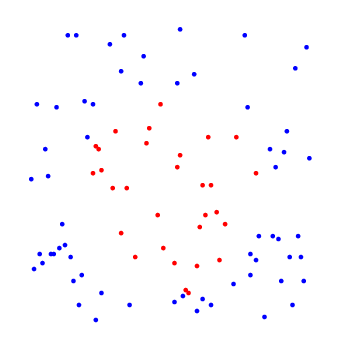
Реализация в системе Octave [ здесь ].
Список литературы
[1] Andrew Ng Machine Learning – http://www.coursera.org/course/ml
[2] Логистическая регрессия: Википедия – http://en.wikipedia.org/wiki/Logistic_regression
