
[
на главную
]
Технология параллельного программирования CUDA
Е.С.Борисов
вторник, 3 февраля 2015 г.
...
на море на океане есть остров,
на том острове дуб стоит,
на дубе сундук висит,
в сундуке — заяц,
в зайце — утка,
в утке — яйцо,
в яйце — игла,
на конце той иглы...
на том острове дуб стоит,
на дубе сундук висит,
в сундуке — заяц,
в зайце — утка,
в утке — яйцо,
в яйце — игла,
на конце той иглы...
-- Русская Народная Сказка
В этой статье мы поговорим об высокопроизводительных параллельных вычислениях, графических ускорителях и технологии CUDA.
1. Введение
Параллельные вычисления давно уже перестали быть специальными технологиями, которыми пользовались лишь в исследовательских центрах. Сегодня методы параллельных вычислений в той или иной степени используются почти в каждой вычислительной машине. Совершенствование элементной базы компьютеров в сочетании с параллельной обработкой данных позволило существенно повысить производительность вычислений.В этой статье мы поговорим об одной из популярных технологий высокопроизводительных вычислений использующей GPU (graphics processing units). Изначально этот класс устройств разрабатывался для обработки графики. Техника совершенствовалась, GPU наращивали производительность и в какой-то момент оказалось, что GPU можно успешно использовать не только для задач компьютерной графики но и как математический сопроцессор для CPU машины, получая при этом существенный прирост в производительности.
Этот класс технологий получил название GPGPU (General-Purpose Graphics Processing Units) -- использование графического процессора для общего назначения. Популярный представитель этого класса -- CUDA (Compute Unified Device Architecture), она была впервые представлена компанией NVIDIA в 2007 году [ 1 ]. CUDA может использоваться на GPU производства NVIDIA, таких как GeForce, Quadro, Tesla. Последняя линейка устройств ( Tesla ) видеовыхода вообще не имеют и предназначены исключительно для высокопроизводительных вычислений.
CUDA работает только с устройствами производства NVIDIA, но это не беда, помимо CUDA существуют и другие аналогичные технологии, например OpenCL и AMD FireStream, но их описание выходит за рамки этой статьи.
2. Аппаратная часть
Эксперименты мы будем ставить на NVIDIA Quadro FX1700, далее в общих чертах рассмотрим архитектуру GPU.

Рис.1: NVIDIA Quadro FX1700 (фото с сайта http://www.thg.ru)
Архитектура GPU построена иначе, чем у универсальных CPU [ 2 ], и в ней изначально заложена определенная специализация. Задачи компьютерной графики предполагают независимую параллельную обработку данных и GPU изначально предназначен для параллельных вычислений. Он спроектирован так, чтобы выполнять большое количество тредов (элементарных параллельных процессов). GPU содержит много относительно простых арифметико-логических устройств (Рис.2), которые объединены в группы, и реализует модель параллельного вычислителя над общей памятью, но с некоторыми особенностями.
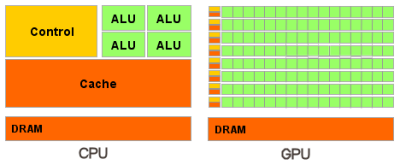
Рис.2: сравнительная схема CPU и GPU (схема с сайта http://www.nvidia.ru)
GPU ориентирован на выполнение программ с большим объемом вычислений (распараллеливание по данным типа SIMD). Память GPU имеет иерархическую структуру и оптимизирована под максимальную пропускную способность. Вместо системы кэшей CPU и сложных арифметико-логических схем (АЛУ), GPU имеет много упрощённых АЛУ, имеющих общую память. Это помогает повысить производительность в вычислительных задачах но несколько усложняет программирование. Для достижения наилучшего ускорения необходимо продумывать стратегии доступа к памяти и учитывать аппаратные особенности.
GPU представляет собой массив потоковых процессоров (Streaming Processor Array), состоящий из кластеров текстурных процессоров (Texture Processor Clusters, TPC). TPC состоит из набора мультипроцессоров (SM – Streaming Multi-processor), каждый из которых содержит несколько потоковых процессоров (SP – Streaming Processors) или ядер. Набор ядер каждого мультипроцессора работает по принципу SIMD (одиночный поток команд, множество потоков данных). На рис.3 представлена общая аппаратная схема работы мультипроцессоров (SM) GPU.
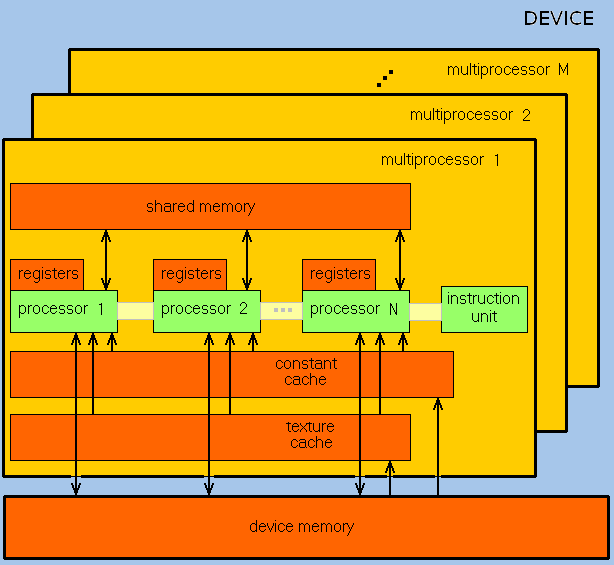
Рис.3: схема работы мультипроцессоров (SM) GPU
В сравнении с универсальным CPU, конструкция GPU налагает ряд дополнительных ограничений для программирования, они зависят от конкретной модели. Для NVIDIA Quadro FX1700 это следующие особенности: GPU не поддерживает рекурсию и вычисления с двойной (double) точностью (возможна только одинарная точность - float).
3. Программная часть
Здесь мы поговорим об программной части CUDA и программировании для GPU.Пакет инструментов для разработчика и библиотеки CUDA можно скачать с сайта NVIDIA . На момент написания этой статьи там доступны пакеты для Windows, Linux и MacOSX. Мы будем использовать ОС Linux, но почти все, что излагается далее, справедливо и для других ОС, возможно с небольшими исправлениями. Описание процедуры инсталляции и настройки среды программирования оставим за рамками статьи и перейдём к компилятору и программам.
Существуют привязки CUDA для разных языков программирования, полный список можно посмотреть на сайте NVIDIA. Здесь для реализации тестовых примеров мы будем использовать CUDA C -- адаптированный для программирования GPU диалект языка C++.
Пакет CUDA-разработчика для Linux содержит компилятор nvcc , который генерирует код для работы с GPU.
$ nvcc --version
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2014 NVIDIA Corporation
Built on Thu_Jul_17_21:41:27_CDT_2014
Cuda compilation tools, release 6.5, V6.5.12
Листинг 1:
версия CUDA
Каждое устройство CUDA имеет специальное свойство -- уровень вычислительных возможностей (compute capability), которое определяет набор доступных устройству возможностей из всего функционала CUDA. Для NVIDIA Quadro FX1700 этот параметр определён как 1.1, поэтому компилятор будем запускать с флагом '-arch sm_11' .
4. Программирование на CUDA C
Программу на CUDA С можно логически разделить на две части, первая часть (управляющая) выполняется на CPU, вторая часть (вычислительная) выполняется на GPU. CPU в терминах CUDA называется host , GPU называется device . На языке CUDA C часть кода, которая должна выполнятся на GPU, называется kernel (ядро), она описывается в виде функции, ниже мы рассмотрим примеры программ.
__global__
void kern() {
// do nothing
}
int main() {
kern<<<1,1>>>();
return 0;
}
Листинг 2:
простейшая CUDA C программа
На листинге 2 представлена простейшая CUDA C программа, она не делает ничего. Ядро, которое описано функцией kern , выполняется на GPU, эта функция имеет спецификатор __global__ , который говорит компилятору, что функция вызывается с CPU и выполняется на GPU. Для функций есть и другие спецификаторы(см.таб.1).
| спецификатор | выполняется | вызывается |
|---|---|---|
| __host__ | host | host |
| __global__ | device | host |
| __device__ | device | device |
На функции выполняемые на GPU налагается ряд ограничений: они не могут содержать рекурсию, не могут иметь переменное число аргументов и не могут иметь static переменные внутри себя.
Ядро на GPU запускается строкой kern<<<1,1>>>() , тройные угловые скобки это специфичный CUDA C синтаксис, значения в этих скобках определяют количество копий ядра, запускаемых на GPU, т.е. количество и конфигурацию параллельных процессов GPU. В данном случае мы запускаем один процесс -- один блок с одним тредом, внутри основного стрима и ожидаем его завершения.
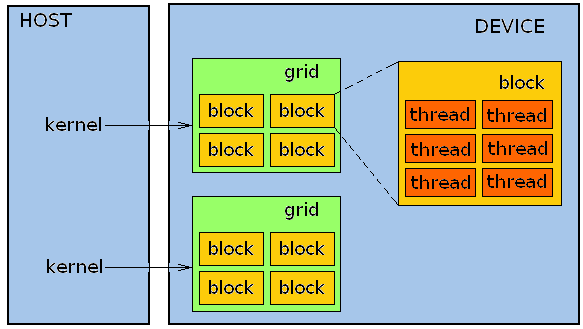
Рис.4: схема организации параллельных процессов
Запуск ядра порождает процессы (треды) на GPU в соответствии с заданным параметрами (рис.4). Всё множество процессов, порождаемых запуском ядра, в терминологии CUDA называеться грид (grid). Грид состоит из блоков (block), блок из тредов (thread). Тред это элементарный параллельный процесс. Треды в блоках и блоки в гриде могут быть представлены в виде одно-, двух- или трёхмерной решетки.
Для FX1700 максимальный размер грида 65535 x 65535 блоков. Максимально возможные значения индексов номера треда в блоке 512 x 512 x 64, но при этом количество тредов в блоке не должно превышать 512.
Ядра можно запускать асинхронно, тогда несколько гридов будут выполняться на GPU параллельно.
При конфигурировании топологии процессов необходимо учитывать аппаратные особенности. Здесь следует ввести понятие варпа. Варп (warp) это группа тредов, размер варпа для FX1700 - 32 треда. Полуварп (half-warp) - половина тредов варпа. Все треды одного варпа выполняются одновременно и синхронно (SIMD) на своём мультипроцессоре. При доступе треда к основной памяти GPU её части могут кэшироваться в локальной памяти данного мультипроцессора. Если все данные, которые требуются тредам полуварпа будут находиться в этом кэше то это может повысить производительность.
GPU имеет сложно организованную память (рис.3), помимо основной (или глобальной) памяти каждый мультипроцессор обладает своей памятью. Программная модель памяти CUDA представлена на рис.5, далее мы рассмотрим типы памяти CUDA и методы работы с ней.
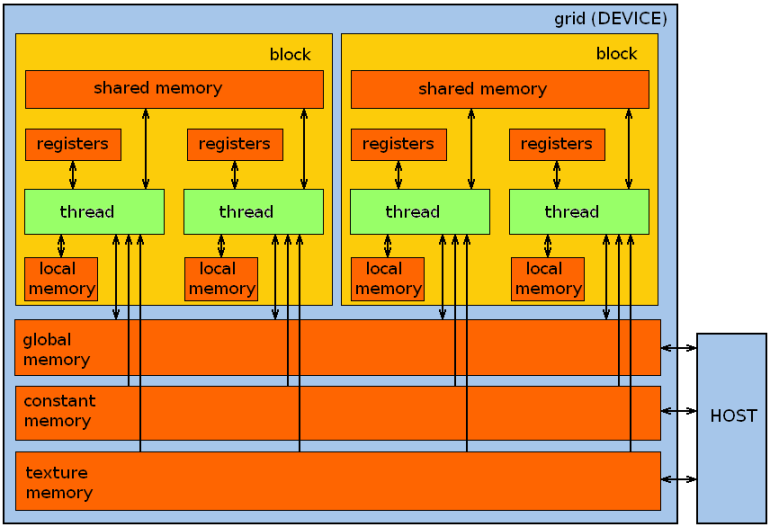
Рис.5: схема организации памяти CUDA-программы
4.1. Основная (глобальная) память
Рассмотрим простой пример работы с основной (глобальной) памятью GPU -- поэлементное сложение векторов (листинг 3).
#define N 128
__global__ void add( int *a, int *b, int *c ) {
int tid = threadIdx.x;
if(tid > N-1) return;
c[tid] = a[tid] + b[tid];
}
int main() {
int host_a[N], host_b[N], host_c[N];
int *dev_a, *dev_b, *dev_c;
for (int i=0; i<N; i++) { host_a[i] = i * i; host_b[i] = - i; }
cudaMalloc( (void**)&dev_a, N * sizeof(int) );
cudaMalloc( (void**)&dev_b, N * sizeof(int) );
cudaMalloc( (void**)&dev_c, N * sizeof(int) );
cudaMemcpy( dev_a, host_a, N * sizeof(int), cudaMemcpyHostToDevice ) ;
cudaMemcpy( dev_b, host_b, N * sizeof(int), cudaMemcpyHostToDevice ) ;
add<<<1,N>>>( dev_a, dev_b, dev_c );
cudaMemcpy( host_c, dev_c, N * sizeof(int), cudaMemcpyDeviceToHost ) ;
for (int i=0; i<N; i++) { printf( "%d + %d = %d\n", host_a[i], host_b[i], host_c[i] ); }
cudaFree( dev_a );
cudaFree( dev_b ); cudaFree( dev_c );
return 0;
}
Листинг 3:
поэлементное сложение векторов
Эта программа генерирует два вектора целых чисел, копирует их в память GPU, выполняет сложение на GPU, результат копируем обратно в память CPU. GPU обычно не работает на прямую с памятью CPU, хотя это технически возможно (нуль-копируемая память). Для начала необходимо выделить память под данные на device, для этого используется фукция cudaMalloc() , после этого копируем данные из памяти host в память device с помощью cudaMemcpy() . Далее для каждого элемента вектора запускается отдельный процесс сложения т.е. в данном случае - 128 тредов. На CPU это могло быть накладно но GPU как раз рассчитан на управление большим количеством вычислительных процессов и всё происходит достаточно быстро. После того как операция завершена с помощью cudaMemcpy() копируем результат обратно на host и освобождаем память device с помощью cudaFree() . В тексте ядра есть переменная threadIdx это системная переменная CUDA, содержащая номер треда, об этом мы поговорим ниже.
4.2. О компоновке тредов и блоков
Как уже говорилось выше, всё множество тредов в блоках и блоков в гриде, порождаемых запуском ядра, можно формировать в виде одно-, двух- или трёхмерной решетки. Размеры решетки зависят от конкретного устройства. Для FX1700 максимальный размер грида 65535 x 65535 блоков. Максимально возможные значения индексов номера треда в блоке 512 x 512 x 64, но при этом количество тредов в блоке не должно превышать 512.На листинге 4 представлен пример следующей организации тредов. Размер блока 8x8x8, что как раз равно 512 тредов на один блок, размер грида 8х32 блока, таким образом общее количество параллельных процессов 131072=8x8x8x8x32.
#define DGX 8
#define DGY 32
#define DBX 8
#define DBY 8
#define DBZ 8
#define N (DBX*DBY*DBZ*DGX*DGY)
__global__ void kern( float *a ) {
int bs = blockDim.x*blockDim.y*blockDim.z;
int idx = threadIdx.x + threadIdx.y*blockDim.x + threadIdx.z*(blockDim.x*blockDim.y)
+ blockIdx.x*bs + blockIdx.y*bs*gridDim.x ;
if(idx > N-1) return;
a[idx] -= 0.5f;
}
int main() {
float host_a[N], host_c[N];
float *dev_a;
srand((unsigned int)time(NULL));
for(int i=0; i<N; i++) { host_a[i] = (float)rand()/(float)RAND_MAX - 0.5f ; }
cudaMalloc( (void**)&dev_a, N * sizeof(float) ) ;
cudaMemcpy( dev_a, host_a, N * sizeof(float), cudaMemcpyHostToDevice ) ;
dim3 blocks(DGX,DGY);
dim3 threads(DBX,DBY,DBZ);
kern<<<blocks,threads>>>( dev_a );
cudaMemcpy( host_c, dev_a, N * sizeof(float), cudaMemcpyDeviceToHost ) ;
for (int i=0; i<N; i++) {
if(host_a[i]-0.5f != host_c[i])
printf( "[%d]\t %.2f -> %.2f\n",i, host_a[i], host_c[i] );
}
cudaFree( dev_a ) ;
return 0;
}
Листинг 4:
пример организации тредов как трехмерной решетки
При этом, адресация выделенной памяти -- линейная и сложный номер треда пересчитывается в индекс ячейки масива памяти.
Для того, что бы задать трех- или двухмерную решетку тредов и/или блоков необходимо определить переменную размеров типа dim3 , и передать её в качестве параметра (в угловых скобках) при запуске ядра. Кроме dim3 CUDA содержит и другие векторные типы char2, int3, float3 и др.
Для определения номера треда и размеров блока и грида в CUDA есть следующие системные переменные (таблица 2).
| тип | имя | назначение |
|---|---|---|
| dim3 | gridDim | размер грида |
| dim3 | blockDim | размер блока |
| uint3 | blockIdx | номер блока в гриде |
| uint3 | threadIdx | номер треда в блоке |
| int | warpSize | количество тредов в варпе |
4.3. Константная память
Здесь мы рассмотрим т.н. константную память, как следует из названия эта память только для чтения, перед запуском ядра host записывает туда данные, которые device использует в работе. В FX1700 объём константной памяти составляет 64K. При этом константная память кэшируется мультипроцессорами и это помогает повысить производительность. Переменные относящиеся к константной памяти GPU объявляются с модификатором __constant__ (листинг 5). Рассмотрим пример программы использующей константную память.
#define N 32
__constant__ float dev_const[2];
__global__ void kern( float *res ) {
int tid = threadIdx.x;
if( tid > N-1 ) return;
res[tid] = dev_const[0] * tid + dev_const[1] * tid*0.5f ;
}
int main( void ) {
float host_const[2] = { 0.34673f, 0.148f };
float host_res[N];
float *dev_res;
cudaMemcpyToSymbol( dev_const, host_const, sizeof(float) );
cudaMalloc( (void**)&dev_res, N * sizeof(float) );
kern<<<1,N>>>( dev_res );
cudaMemcpy( host_res, dev_res, N * sizeof(float), cudaMemcpyDeviceToHost );
for (int i=0; i<N; i++) { printf( "%.2f\n", host_res[i] ); }
printf("time spent executing by the GPU: %.2f millseconds\n", gpuTime );
cudaFree( dev_res );
return 0;
}
Листинг 5:
работа с константной памятью
В этой программе мы объявляем константы для device с помощью модификатора __constant__ . Используя функцию cudaMemcpyToSymbol записываем туда значения и запускаем ядро, которое использует эти константы в своих вычислениях. После завершения работы ядра результат копируем в память host.
4.4. Разделяемая память
Каждый блок может иметь внутреннюю разделяемую его тредами память. В FX1700 для этих целей на каждом мультипроцессоре отведено 16K.
#define M 128
#define N (M*256)
__global__ void kern( float *a, float *c ) {
__shared__ float s[M];
int tid = threadIdx.x;
if(tid > M-1) return ;
for(int i=tid*(N/M) ; i<(N/M)*(1+tid) ;i++ ) { s[tid] = a[i] + 1.0f ; }
__syncthreads();
s[M-1-tid] *= 0.35f ;
__syncthreads();
for(int i=tid*(N/M) ; i<(N/M)*(1+tid) ;i++ ) { c[i] = s[tid] * 0.82f ; }
}
int main() {
float host_a[N], host_c[N];
float *dev_a, *dev_c;
for(int i=0 ; i<N ; i++) { host_a[i] = 1.0f; }
cudaMalloc( (void**)&dev_a, N * sizeof(float) ) ;
cudaMalloc( (void**)&dev_c, N * sizeof(float) ) ;
cudaMemcpy( dev_a, host_a, N * sizeof(float), cudaMemcpyHostToDevice ) ;
cudaEventRecord( start, 0 ) ;
kern<<<1,M>>>( dev_a, dev_c );
cudaEventRecord( stop, 0 ) ;
cudaMemcpy( host_c, dev_c, N * sizeof(float), cudaMemcpyDeviceToHost ) ;
for(int i=0; i<N; i++) {
if(host_c[i] != (host_a[i]+1.0f)*0.35f*0.82f )
printf( "error [%d] %f -> %f\n",i, host_a[i], host_c[i] );
}
cudaFree( dev_a ) ; cudaFree( dev_c ) ;
return 0;
}
Листинг 6:
работа с разделяемой памятью
На листинге 6 представлен пример работы с разделяемой памятью, которая объявляется внутри ядра с модификатором __shared__ . Каждый тред записывает в "свою" ячейку разделяемой памяти данные, затем изменяет данные в "чужой" ячейке, после этого результат переписывается в основную память GPU, а затем и в память CPU.
Поскольку треды конкурируют между собой за общий ресурс (память), то возникает возможность конфликтов и неоднозначностей между тредами. Появляется необходимость в механизме синхронизации тредов. Для этой цели можно использовать функцию __syncthreads() . Этот метод работает для тредов одного блока. Выполнившие __syncthreads() треды блока ожидают остальные треды этого блока, пока все выполнят __syncthreads() . В этом случае если один из тредов по логике программы никогда не дойдёт до __syncthreads() то программа зависает (дедлок).
4.5. Текстурная память
В этом разделе мы поговорим о текстурной памяти. Как и константная она доступна device только для чтения и обладает при этом рядом особенностей. Текстурная (texture) память , как и следует из названия, предназначена главным образом для работы с текстурами. Текстурирование это процесс наложения текстуры (картинки) на полигон. Текстурная память оптимизирована под выборку 2D данных и имеет специфические особенности в адресации: аппаратная интерполяция соседних значений, аппаратная обработка выхода за границу массива и др. Из текстурной памяти можно читать данные только специальных типов CUDA, имеющих размер 1, 2, 4, 8 или 16 байт, и только с помощью специальных функций - tex1D, tex2D или tex1Dfetch, tex2Dfetch. Текстурная память физически не отделена от глобальной памяти и её размер ограничивается только максимальным размером памяти устройства, при этом её части могут кэшироваться на мультипроцессорах. В FX1700 размер основной (глобальной) памяти 512MB.Рассмотрим простейший пример работы с текстурной памятью (листинг 7).
#define N 256
texture<int> dev_tex_a;
__global__ void kern( int *c ) {
int tid = threadIdx.x;
if(tid > N-1) return;
c[tid] = tid + tex1Dfetch(dev_tex_a,tid);
}
int main() {
int host_a[N], host_c[N];
int *dev_a, *dev_c;
for (int i=0; i<N; i++) { host_a[i] = i; }
cudaMalloc( (void**)&dev_a, N * sizeof(int) );
cudaBindTexture( NULL, dev_tex_a, dev_a, N * sizeof(int) );
cudaMalloc( (void**)&dev_c, N * sizeof(int) );
cudaMemcpy( dev_a, host_a, N * sizeof(int), cudaMemcpyHostToDevice );
kern<<<1,N>>>( dev_c );
cudaMemcpy( host_c, dev_c, N * sizeof(int), cudaMemcpyDeviceToHost );
for (int i=0; i<N; i++) { printf( "%d\n", host_c[i] ); }
cudaUnbindTexture( dev_tex_a );
cudaFree( dev_a ) ;
cudaFree( dev_c );
return 0;
}
Листинг 7:
работа с текстурной памятью
В этой программе мы объявляем текстуру с помощью шаблона texture , выделяем (как обычно) участок глобальной памяти device с помощью cudaMalloc() , а за тем привязываем его к текстуре с помощью cudaBindTexture() . Запускаем ядро, выполняем вычисления, вынимая данные из тектуры с помощью tex1Dfetch() . Копируем результат обратно на host, отвязываем текстуру с помощью cudaUnbindTexture() и освобождаем память с помощью cudaFree() .
4.6. Атомарные операции
В этом разделе мы поговорим о синхронизации процессов в разных блоках. Функция __syncthreads() , о которой мы говорили в разделе посвящённом разделяемой памяти, позволяет синхронизировать процессы в рамках одного блока. Для разрешения конфликтов между процессами из разных блоков за доступ к глобальной памяти можно использовать т.н. атомарные операции, которые являются реализацией механизма критических секций для GPU. Рассмотрим простой пример - операция инкремента (увеличения на единицу) состоит из трёх действий: прочитать значение из памяти, добавить единицу, записать результат обратно в память. Когда несколько процессов пытаются выполнить эту процедуру параллельно над одной областью памяти могут возникать конфликты. Помочь может атомарная операция сложения, она блокирует рабочую область памяти для других процессов пока все три действия не будут завершены.
#define N 128
__global__ void kern( int *a ) {
int tid = blockIdx.x;
if (tid > N-1) return ;
for(int i=0;i<N;i++) atomicAdd( (a+i) , 1 );
}
int main(){
int host_a[N];
int *dev_a;
cudaMalloc( (void**)&dev_a, N * sizeof(int) );
cudaMemset( dev_a, 0, N*sizeof(int) );
kern<<<N,1>>>( dev_a );
cudaMemcpy( host_a, dev_a, N * sizeof(int), cudaMemcpyDeviceToHost );
for (int i=0; i<N; i++) { if(host_a[i]!=N) printf( "error [%d] -> %d\n",i , host_a[i] ); }
cudaFree( dev_a );
return 0;
}
Листинг 8:
работа с атомарными операциями
На листинге 8 представлен простой пример работы с атомарными операциями. В памяти выделяется массив из целых чисел, туда записываются нулевые значения, далее каждый процесс увеличивает на 1 все ячейки этого массива. Если вместо атомарного сложения atomicAdd() использовать обычный инкремент то результат может быть некорректный.
4.7. Параллельный запуск нескольких ядер на GPU
В этом разделе мы поговорим об параллельном запуске нескольких ядер на GPU. Помимо уже описанных форм организации параллельных процессов, в CUDA существует возможность запустить более одного грида на GPU асинхронно, т.е. при запуске ядра основная часть программы на host не дожидается завершения работы device, но сразу возвращает управление. Выполнив после этого некоторую часть своей программы, host может дождаться завершения всех порождённых им гридов используя инструменты синхронизации. Описанного эффекта можно добиться создав несколько очередей выполнения или в терминологии CUDA - стримов (stream) . На листинге 9 представлен пример работы со стримами.
#define N 64
__global__ void kernel1( float *a, float *c ) {
int idx = threadIdx.x ;
if (idx > N-1) return;
c[idx] = a[idx]*a[idx];
}
__global__ void kernel2( float *a, float *c ) {
int idx = blockIdx.x ;
if (idx > N-1) return;
c[idx] = __cosf(a[idx]);
}
int main( void ) {
float host_a[N], host_c0[N], host_c1[N];
float *dev_a0, *dev_c0;
float *dev_a1, *dev_c1;
cudaStream_t stream0, stream1;
srand((unsigned int)time(NULL));
for (int i=0; i<N; i++) { host_a[i] = (float)rand()/(float)RAND_MAX; }
cudaMalloc( (void**)&dev_a0, N * sizeof(float) );
cudaMalloc( (void**)&dev_c0, N * sizeof(float) );
cudaMalloc( (void**)&dev_a1, N * sizeof(float) );
cudaMalloc( (void**)&dev_c1, N * sizeof(float) );
cudaMemcpy( dev_a0, host_a, N * sizeof(float), cudaMemcpyHostToDevice );
cudaMemcpy( dev_a1, host_a, N * sizeof(float), cudaMemcpyHostToDevice );
cudaStreamCreate( &stream0 );
cudaStreamCreate( &stream1 );
kernel1<<<1,N,0,stream0>>>( dev_a0, dev_c0 );
kernel2<<<N,1,0,stream1>>>( dev_a1, dev_c1 );
cudaStreamSynchronize( stream0 );
cudaStreamSynchronize( stream1 );
cudaMemcpy( host_c0, dev_c0, N * sizeof(float), cudaMemcpyDeviceToHost );
cudaMemcpy( host_c1, dev_c1, N * sizeof(float), cudaMemcpyDeviceToHost );
for (int i=0; i<N; i++) { printf("0: [%d]\t%.2f -> %.2f\n",i,host_a[i],host_c0[i]); }
for (int i=0; i<N; i++) { printf("1: [%d]\t%.2f -> %.2f\n",i,host_a[i],host_c1[i]); }
cudaFree( dev_a0 ); cudaFree( dev_c0 ); cudaFree( dev_a1 ); cudaFree( dev_c1 );
cudaStreamDestroy( stream0 );
cudaStreamDestroy( stream1 );
return 0;
}
Листинг 9:
работа с несколькими стримами.
По умолчанию в CUDA-программе есть только одна исполняемая очередь или нуль-стрим. В представленной выше программе мы с помощью cudaStreamCreate() создаём ещё два стрима stream0, stream1 и запускаем два ядра во вновь созданные стримы, добавив соответствующий параметр при запуске ядра. Далее мы ждём пока оба ядра завершат работу, используя cudaStreamSynchronize() , переписываем результат в память CPU и закрываем оба отработанных стрима с помощью cudaStreamDestroy() .
4.8. Асинхронное копирование данных и блокированная память
В этом разделе мы поговорим об асинхронном копировании данных между памятью CPU и GPU. В отличии от обычного (синхронного) копирования процедура асинхронного копирования происходит параллельно с основным стримом, т.е. вызов процедуры асинхронного копирования порождает параллельный процесс и тут же возвращает управление не дожидаясь завершения копирования. Это может сокращать время простоя и увеличивать производительность. Надо отметить, что не все устройства с поддержкой CUDA имеют эту функциональность, она именуется device overlap. Это означает, что GPU может одновременно исполнять ядро и копировать данные между памятью GPU и CPU.Перед тем как асинхронно копировать данные из памяти хоста на девайс и обратно необходимо заблокировать эту область памяти на хосте. Блокировка области памяти (page-locked) означает, что ОС хоста запрещается перемещать данные из этой области физической памяти, т.е. к этой области памяти нельзя применять свопинг и т.п. Этот метод нужно использовать осторожно, потому как мы лишаемся всех преимуществ виртуальной памяти, и должны следить за тем, что бы у нас оставалось достаточно физической памяти для работы.
#define N 32
__global__ void kernel1( float *a, float *c ) {
int idx = threadIdx.x;
if (idx > N-1) return;
c[idx] = a[idx] + 0.1f;
}
__global__ void kernel2( float *a, float *c ) {
int idx = blockIdx.x ;
if (idx > N-1) return;
c[idx] = a[idx] - 0.1f;
}
int main( void ) {
float *host_a, *host_c0, *host_c1;
float *dev_a0, *dev_c0;
float *dev_a1, *dev_c1;
cudaDeviceProp prop;
int dev;
cudaStream_t stream0, stream1;
cudaGetDevice( &dev ) ;
cudaGetDeviceProperties( &prop, dev ) ;
if(!prop.deviceOverlap) { printf( "Device will not handle overlaps\n" ); return 0; }
cudaHostAlloc( (void**)&host_a, N * sizeof(float), cudaHostAllocDefault ) ;
cudaHostAlloc( (void**)&host_c0, N * sizeof(float), cudaHostAllocDefault ) ;
cudaHostAlloc( (void**)&host_c1, N * sizeof(float), cudaHostAllocDefault ) ;
srand((unsigned int)time(NULL));
for (int i=0; i<N; i++) { host_a[i] = (float)rand()/(float)RAND_MAX; }
cudaStreamCreate( &stream0 ) ;
cudaStreamCreate( &stream1 ) ;
cudaMalloc( (void**)&dev_a0, N * sizeof(float) ) ;
cudaMalloc( (void**)&dev_c0, N * sizeof(float) ) ;
cudaMalloc( (void**)&dev_a1, N * sizeof(float) ) ;
cudaMalloc( (void**)&dev_c1, N * sizeof(float) ) ;
cudaMemcpyAsync( dev_a0, host_a, N * sizeof(float), cudaMemcpyHostToDevice, stream0 ) ;
cudaMemcpyAsync( dev_a1, host_a, N * sizeof(float), cudaMemcpyHostToDevice, stream1 ) ;
kernel1<<<1,N,0,stream0>>>( dev_a0, dev_c0 );
kernel2<<<N,1,0,stream1>>>( dev_a1, dev_c1 );
cudaMemcpyAsync( host_c0, dev_c0, N * sizeof(float), cudaMemcpyDeviceToHost, stream0 ) ;
cudaMemcpyAsync( host_c1, dev_c1, N * sizeof(float), cudaMemcpyDeviceToHost, stream1 ) ;
cudaStreamSynchronize( stream0 ) ; cudaStreamSynchronize( stream1 ) ;
for (int i=0; i<N; i++) { printf("0: [%d]\t%.2f -> %.2f\n",i,host_a[i],host_c0[i]); }
for (int i=0; i<N; i++) { printf("1: [%d]\t%.2f -> %.2f\n",i,host_a[i],host_c1[i]); }
cudaFreeHost( host_a ) ; cudaFreeHost( host_c0 ) ; cudaFreeHost( host_c1 ) ;
cudaFree( dev_a0 ) ; cudaFree( dev_c0 ) ; cudaFree( dev_a1 ) ; cudaFree( dev_c1 ) ;
cudaStreamDestroy( stream0 ) ; cudaStreamDestroy( stream1 ) ;
return 0;
}
Листинг 10:
использование асинхронного копирования.
На листинге 10 приведен пример использования асинхронного копирования. В начале проверяем с помощью cudaGetDeviceProperties() поддерживает ли устройство overlap, выделяем блокированную память на хосте с помощью cudaHostAlloc() , выделяем память на GPU и запускаем асинхронное копирование данных на GPU cudaMemcpyAsync() , запускаем ядра в созданные стримы и асинхронное копирование результата с GPU, после этого ожидаем завершения работы стримов с помощью cudaStreamSynchronize() . Когда стримы завершатся - печатаем результат и освобождаем ресурсы - cudaFreeHost() .
В заключение надо отметить ещё один момент, для совместного использования двумя стримами одного и того же буфера блокированной памяти необходимо использовать флаг cudaHostAllocPortable в противном случае блокированным этот буфер будет считать только один стрим.
4.9. Использование памяти CPU
Выше мы упомянули о возможности доступа GPU к памяти CPU. Этого можно достичь применив т.н. нуль-копируемую память. Выделенная область памяти host блокируется и отображается в память device. На листинге 11 представлен пример работы с нуль-копируемой памятью.
#define N 32
__global__ void kern( float *a, float *c ) {
int tid = threadIdx.x;
if(tid > N-1) return;
c[tid] = a[tid] + 1.0f;
}
int main( void ) {
float *dev_a, *dev_c;
float *host_a, *host_c;
cudaDeviceProp prop;
int dev;
cudaGetDevice( &dev ) ;
cudaGetDeviceProperties( &prop, dev ) ;
if(prop.canMapHostMemory!=1) {
printf( "Device can not map memory.\n" );
return 0;
}
cudaSetDeviceFlags( cudaDeviceMapHost ) ;
cudaHostAlloc( (void**)&host_a, N*sizeof(float), cudaHostAllocWriteCombined
| cudaHostAllocMapped ) ;
cudaHostAlloc( (void**)&host_c, N*sizeof(float), cudaHostAllocMapped ) ;
cudaHostGetDevicePointer( &dev_a, host_a, 0 ) ;
cudaHostGetDevicePointer( &dev_c, host_c, 0 ) ;
for (int i=0; i<N; i++) { host_a[i] = (float)i; }
kern<<<1,N>>>( dev_a, dev_c );
cudaThreadSynchronize() ;
for (int i=0; i<N; i++) { printf( "%.2f => %.2f\n", host_a[i], host_c[i] ); }
cudaFreeHost( host_a ) ; cudaFreeHost( host_c ) ;
return 0;
}
Листинг 11:
использование нуль-копируемой памяти.
В начале мы проверяем поддерживает ли устройство отображение памяти. Далее включаем эту функциональность с помощью cudaSetDeviceFlags(cudaDeviceMapHost) . Выделяем блокированную память CPU с помощью cudaHostAlloc() , при этом для входного буфера можно указать флаг cudaHostAllocWriteCombined , который устанавливает особый режим кэширования этой области памяти для CPU, это ускорят чтение этих данных для GPU, но при этом скорость работы с ними CPU существенно падает. Отображаем выделенные буферы памяти CPU в память GPU с помощью cudaHostGetDevicePointer() и запускаем ядро. Перед тем как печатать результат необходимо вызвать cudaThreadSynchronize() , что бы буферы памяти GPU и CPU синхронизировались. В конце работы освобождаем ресурсы.
4.10. Операции с матрицами
Помимо базовой фукциональности в пакете CUDA поставляются дополнительные библиотеки. В этом разделе мы поговорим про библиотеку методов линейной алгебры cuBLAS, которая является адаптированной для CUDA вариантом библиотеки BLAS (Basic Linear Algebra Subroutines). Билиотеку cuBLAS можно использовать для выполнения вычислений с векторами и матрицами.
#include "cublas_v2.h"
// размер матрицы
#define M 5
#define N 6
// конвертер индексов матрицы в линейный адрес
#define IDX2F(i,j,ld) ((((j)-1)*(ld))+((i)-1))
int main() {
float* dev_A=NULL;
float* host_A=NULL;
float* dev_B=NULL;
float* host_B=NULL;
float* dev_C=NULL;
float* host_C=NULL;
float* dev_D=NULL;
float* host_D=NULL;
cublasHandle_t handle;
float a=1.0f;
float b=1.0f;
// выделяем память CPU для матриц
host_A = (float *)malloc(M*N*sizeof(*host_A)) ;
host_B = (float *)malloc(M*N*sizeof(*host_B)) ;
host_C = (float *)malloc(M*N*sizeof(*host_C)) ;
host_D = (float *)malloc(M*M*sizeof(*host_D)) ;
// заполняем матрицы используя конвертор индексов
for(int j = 1; j <= N; j++) { for(int i = 1; i <= M; i++) {
host_A[IDX2F(i,j,M)] = (float)1.3f;
host_B[IDX2F(i,j,M)] = (float)0.5f;
}
}
// выделяем память GPU для матрицы
cudaMalloc ((void**)&dev_A, M*N*sizeof(*host_A));
cudaMalloc ((void**)&dev_B, M*N*sizeof(*host_B));
cudaMalloc ((void**)&dev_C, M*N*sizeof(*host_C));
cudaMalloc ((void**)&dev_D, M*M*sizeof(*host_D));
// инициализируем CUBLAS
cublasCreate(&handle);
// копируем содержимое матриц из памяти CPU в память GPU
cublasSetMatrix (M, N, sizeof(*host_A), host_A, M, dev_A, M);
cublasSetMatrix (M, N, sizeof(*host_B), host_B, M, dev_B, M);
a=1.0f; b=1.0f;
// матричное сложение C=a*A+b*B
cublasSgeam(handle,CUBLAS_OP_N,CUBLAS_OP_N,M,N,&a,dev_A,M,&b,dev_B,M,dev_C,M);
// копируем содержимое матрицы обратно в память CPU из памяти GPU
cublasGetMatrix (M, N, sizeof(*host_C), dev_C, M, host_C, M)
;
// печатаем результат
printf("A+B:\n");
for(intj=1;j<=N;j++){for(inti=1;i<=M;i++){printf("%7.2f",host_C[IDX2F(i,j,M)]);}printf("\n");}
b=0.0f;
// матричное умножение D=a*A*transp(B)+b*D
cublasSgemm(handle,CUBLAS_OP_N,CUBLAS_OP_T,M,M,N,&a,dev_A,M,dev_B,M,&b,dev_D,M);
// копируем содержимое матрицы обратно в память CPU из памяти GPU
cublasGetMatrix (M, M, sizeof(*host_D), dev_D, M, host_D, M);
// печатаем результат
printf("A*Tr(B):\n");
for(intj=1;j<=M;j++){for(inti=1;i<=M;i++){printf("%7.2f",host_D[IDX2F(i,j,M)]);}printf("\n");}
a=0.5f;
// умножить каждый второй элемент матрицы на скаляр A=a*A
cublasSscal(handle, M*N, &a, dev_A, 2);
// копируем содержимое матрицы обратно в память CPU из памяти GPU
cublasGetMatrix (M, N, sizeof(*host_C), dev_C, M, host_C, M);
// печатаем результат
printf("a*A:\n");
for(intj=1;j<=N;j++){for(inti=1;i<=M;i++){printf("%7.2f",host_A[IDX2F(i,j,M)]);}printf("\n");}
// освобождаем ресурсы
cudaFree(dev_A); cudaFree(dev_B); cudaFree(dev_C); cudaFree(dev_D);
free(host_A); free(host_B); free(host_C); free(host_D);
cublasDestroy(handle)
;
return 0;
}
Листинг 12:
использование сuBLAS
На листинге 12 представлен пример использования cuBLAS, эта программа генерирует две матрицы чисел одинакового размера, выполняет с ними действия - сложение, транспонирование и умножение. В начале мы выделяем память для данных обычным способом, далее инициализируем cuBLAS с помощью cublasCreate() , копируем данные host на device с помощью cublasSetMatrix() . После этого выполняем операции с матрицами: сложение - cublasSgeam() , умножение - cublasSgemm() , домножение на скаляр - cublasSscal() . Каждая из этих функций cuBLAS самостоятельно формирует и запускает на device нужное количество процессов, при этом каждая такая функция может выполнять сразу несколько операций, например - транспонирование и умножение. После завершения вычислений результат копируем обратно на host с помощью cublasGetMatrix() , печатаем результат и освобождаем ресурсы - cublasDestroy() .
4.11. Оценка затраченного на вычисления времени
Для того, что бы подсчитать время затраченное на выполнение вычислений на GPU в CUDA существует механизм событий (event) или временных меток.
cudaEvent_t start, stop;
float gpuTime;
cudaEventCreate( &start );
cudaEventCreate( &stop );
cudaEventRecord( start, 0 );
...
cudaEventRecord( stop, 0 ) ;
cudaEventSynchronize( stop ) );
cudaEventElapsedTime( &gpuTime, start, stop ) ;
printf("time spent executing by the GPU: %.2f millseconds\n", gpuTime );
cudaEventDestroy( start) ;
cudaEventDestroy( stop) ;
Листинг 13:
оценка времени выполнения.
На листинге 13 приведена чать кода, которая замеряет время выполнения программы. В начале создаём временные метки start, stop с помощью cudaEventCreate() , далее фиксируем время старта с помощью cudaEventRecord() , выполняем вычисления, фиксируем время завершения. Поскольку некоторые операции могут выполняться асинхронно Вызываем cudaEventSynchronize() , что бы метка записалась корректно. Далее вычисляем разницу во времени с помощью cudaEventElapsedTime() и печатаем результат.
5. Заключение
На сегодня тема GPGPU и CUDA в частности является перспективной и востребованной. CUDA широко применяется для решения задач обработки изображений, машинного обучения и инженерных расчётов, часто позволяя относительно недорого и без громоздкой аппаратуры обеспечить удовлетворительную производительность.Исходники программ можно скачать [ здесь ].
Список литературы
- Джейсон Сандерс, Эдвард Кэндрот Технология CUDA в примерах. Введение в программирование графических процессоров. -- ДМК Пресс, 2011 г.
-
Дымченко Лев Вычисления на GPU. Особенности архитектуры AMD/ATI Radeon.
-- http://www.ixbt.com/video3/rad.shtml - CUDA Toolkit Documentation -- http://docs.nvidia.com/cuda
-
nVidia GeForce GTX 260 и 280: новое поколение видеокарт
-- http://www.thg.ru/graphic/geforce_gtx_260_280/print.html - CUDA Toolkit Documentation: cuBLAS -- http://docs.nvidia.com/cuda/cublas
